
Attention이 나온 이유?
Attention은 LSTM 혹은 RNN으로 만들어진 Encoder Decoder에서 나온 개념입니다. Encoder에 입력에 대한 정보를 은닉벡터로 함축시켜 전달을 하는데, 이 은닉벡터가 모든 정보를 담기 어렵다는 이유에서 탄생하게 되었습니다. Decoder에서 항상 Encoder의 마지막 은닉벡터를 활용하는데, 이 정도에다 +로 Encoder에서 현재 위치와 연관된 단어에 대한 은닉벡터를 다시한번 봐서(집중해서 - Attention) 은닉벡터로 표현하지 못한 부분까지 보려는 노력을 하게됩니다.
Attention의 이해
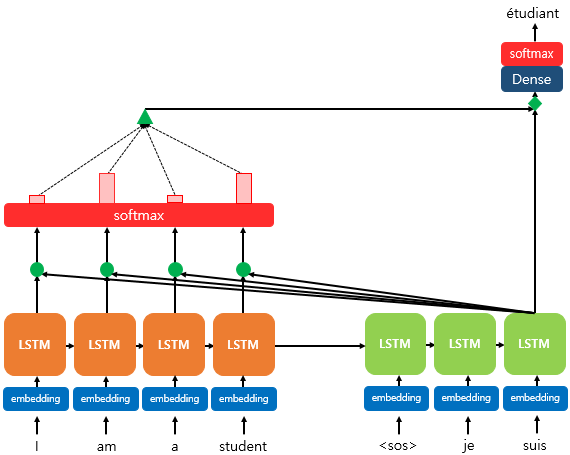
어텐션이 계산되는 과정을 간단히 설명드리고 우리가 궁금한 Query, Key, Value를 알아보겠습니다.
Encoder에서 들어온 값은 I am a student입니다. 이에 대하여 Decoder로 3번째 단어를 유추하는 상황입니다. Encoder에서는 단어를 하나씩 LSTM에 넣어서 은닉벡터를 구성했을 것입니다. 각 LSTM에는 그 상황에서의 은닉벡터를 가지고 있죠. Decoder에서 현재 유추하려고 하는 단어를 만들 때, 가장 관련되어 있는 인코더의 단어가 무엇인지 찾게될 것입니다. 초록색 동그라미와 Softmax가 그 과정입니다. 그 결과는 softmax에 위에 빨간 기둥으로 보여주죠. am, student가 영향을 많이 끼치겠군요. 이렇게 얼마나 영향을 끼칠지에 대한 정보가 Attention Score입니다. 그리고 그 각각의 단어들을 어떠한 초록색 세모 연산을 통해 하나의 벡터로 만들어줍니다. 이 벡터가 Attention Value입니다. Decoder에서 집중해서 봐야하는 정보에 대하여 다시 상기시켜주는 값이죠. 이 때 초록색 세모의 연산 방법은 곱하기가 있을 수도 있고, Concat 연산이 있을수도 있겠죠. 그 방법에 따라 dot - Attention, 바디나우 - Attention(바디나우는 사람 이름) 등 다양한 Attention으로 분류됩니다.
결과적으로 우리가 찾고자하는 값은 Attention Value이며 이를 통해 좀 더 Decoder에서 원하는 정보를 자세히 보게 됩니다.
Attention에서 Query, Key, Value는?
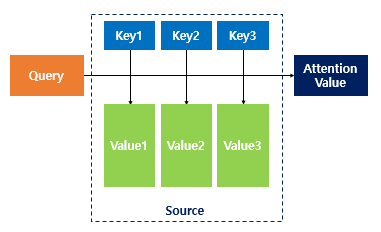
Attention의 Attention Value를 뽑아내는 과정을 단순하게 위처럼 표현할 수 있어요. Key-Value는 딕셔너리죠. Json과 같은 자료형이라고 생각하시면 편합니다. Query는 현재 우리가 유추해야하는 Decoder의 은닉상태에요. 위 예시에서는 3번째 Decoder의 LSTM으로 나온 은닉상태의 벡터입니다. Key는 Encoder의 은닉벡터들이죠(이해가 어려울 수 있어요..). 우리가 위에서 초록색 동그라미 연산으로 지금 예측해야하는 디코더의 은닉상태(Query)와 각각의 Encoder의 각 LSTM 시점에 있던 은닉상태(Key)가 얼마나 연관이 있는지 알아보잖아요? 그 때 Encoder 각 LSTM셀에서 나오게 되는 값이죠. 그리고 Attention Score가 나오면 그 값을 적용해서 Attention Value를 뽑아내야죠. 그 때 Key와 연관된 Value를 꺼내서 Attention Score와 연산하여 Attention Value를 만들어주는거에요.
Query - Decoder의 은닉상태(현재 우리가 유추해야하기 위한 정보에 대한 은닉상태)
Key - Encoder의 은닉상태들(Query와 얼마나 연관되어있는지 체크해야할 Encoder의 LSTM셀의 은닉벡터들)
Value - Encoder의 은닉상태들(Key로 꺼내온 Encoder의 은닉벡터 값들)
Reference
'Artificial intelligence > Etc' 카테고리의 다른 글
| [Error] hdbscan 패키지 설치 에러 (0) | 2023.01.02 |
|---|---|
| Hello RL : Frozen Lake 소개 및 기본 코드 (1) | 2022.09.15 |
| Object Detection의 개요 (0) | 2022.07.30 |
| 모델 평가(Evaluation) (0) | 2022.07.12 |
| Sklearn 라이브러리를 활용하여 데이터 전처리하기 (0) | 2022.07.08 |